


Note
Click here to download the full example code
Training Transformer models using Pipeline Parallelism¶
Author: Pritam Damania
This tutorial demonstrates how to train a large Transformer model across multiple GPUs using pipeline parallelism. This tutorial is an extension of the Sequence-to-Sequence Modeling with nn.Transformer and TorchText tutorial and scales up the same model to demonstrate how pipeline parallelism can be used to train Transformer models.
Prerequisites:
Define the model¶
In this tutorial, we will split a Transformer model across two GPUs and use
pipeline parallelism to train the model. The model is exactly the same model
used in the Sequence-to-Sequence Modeling with nn.Transformer and TorchText tutorial,
but is split into two stages. The largest number of parameters belong to the
nn.TransformerEncoder layer.
The nn.TransformerEncoder
itself consists of nlayers of nn.TransformerEncoderLayer.
As a result, our focus is on nn.TransformerEncoder and we split the model
such that half of the nn.TransformerEncoderLayer are on one GPU and the
other half are on another. To do this, we pull out the Encoder and
Decoder sections into seperate modules and then build an nn.Sequential
representing the original Transformer module.
import sys
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import tempfile
from torch.nn import TransformerEncoder, TransformerEncoderLayer
if sys.platform == 'win32':
print('Windows platform is not supported for pipeline parallelism')
sys.exit(0)
if torch.cuda.device_count() < 2:
print('Need at least two GPU devices for this tutorial')
sys.exit(0)
class Encoder(nn.Module):
def __init__(self, ntoken, ninp, dropout=0.5):
super(Encoder, self).__init__()
self.pos_encoder = PositionalEncoding(ninp, dropout)
self.encoder = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.init_weights()
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src):
# Need (S, N) format for encoder.
src = src.t()
src = self.encoder(src) * math.sqrt(self.ninp)
return self.pos_encoder(src)
class Decoder(nn.Module):
def __init__(self, ntoken, ninp):
super(Decoder, self).__init__()
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, inp):
# Need batch dimension first for output of pipeline.
return self.decoder(inp).permute(1, 0, 2)
PositionalEncoding module injects some information about the
relative or absolute position of the tokens in the sequence. The
positional encodings have the same dimension as the embeddings so that
the two can be summed. Here, we use sine and cosine functions of
different frequencies.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
Load and batch data¶
The training process uses Wikitext-2 dataset from torchtext. The
vocab object is built based on the train dataset and is used to numericalize
tokens into tensors. Starting from sequential data, the batchify()
function arranges the dataset into columns, trimming off any tokens remaining
after the data has been divided into batches of size batch_size.
For instance, with the alphabet as the sequence (total length of 26)
and a batch size of 4, we would divide the alphabet into 4 sequences of
length 6:
These columns are treated as independent by the model, which means that
the dependence of G and F can not be learned, but allows more
efficient batch processing.
import io
import torch
from torchtext.utils import download_from_url, extract_archive
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
url = 'https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-2-v1.zip'
test_filepath, valid_filepath, train_filepath = extract_archive(download_from_url(url))
tokenizer = get_tokenizer('basic_english')
vocab = build_vocab_from_iterator(map(tokenizer,
iter(io.open(train_filepath,
encoding="utf8"))))
def data_process(raw_text_iter):
data = [torch.tensor([vocab[token] for token in tokenizer(item)],
dtype=torch.long) for item in raw_text_iter]
return torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))
train_data = data_process(iter(io.open(train_filepath, encoding="utf8")))
val_data = data_process(iter(io.open(valid_filepath, encoding="utf8")))
test_data = data_process(iter(io.open(test_filepath, encoding="utf8")))
device = torch.device("cuda")
def batchify(data, bsz):
# Divide the dataset into bsz parts.
nbatch = data.size(0) // bsz
# Trim off any extra elements that wouldn't cleanly fit (remainders).
data = data.narrow(0, 0, nbatch * bsz)
# Evenly divide the data across the bsz batches.
data = data.view(bsz, -1).t().contiguous()
return data.to(device)
batch_size = 20
eval_batch_size = 10
train_data = batchify(train_data, batch_size)
val_data = batchify(val_data, eval_batch_size)
test_data = batchify(test_data, eval_batch_size)
Functions to generate input and target sequence¶
get_batch() function generates the input and target sequence for
the transformer model. It subdivides the source data into chunks of
length bptt. For the language modeling task, the model needs the
following words as Target. For example, with a bptt value of 2,
we’d get the following two Variables for i = 0:
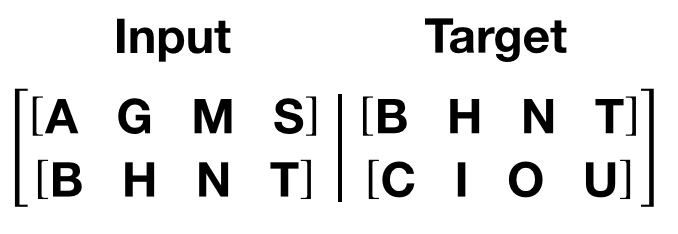
It should be noted that the chunks are along dimension 0, consistent
with the S dimension in the Transformer model. The batch dimension
N is along dimension 1.
bptt = 35
def get_batch(source, i):
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].view(-1)
# Need batch dimension first for pipeline parallelism.
return data.t(), target
Model scale and Pipe initialization¶
To demonstrate training large Transformer models using pipeline parallelism,
we scale up the Transformer layers appropriately. We use an embedding
dimension of 4096, hidden size of 4096, 16 attention heads and 12 total
transformer layers (nn.TransformerEncoderLayer). This creates a model with
~1.4 billion parameters.
We need to initialize the RPC Framework since Pipe depends on the RPC framework via RRef which allows for future expansion to cross host pipelining. We need to initialize the RPC framework with only a single worker since we’re using a single process to drive multiple GPUs.
The pipeline is then initialized with 8 transformer layers on one GPU and 8 transformer layers on the other GPU.
Note
For efficiency purposes we ensure that the nn.Sequential passed to
Pipe only consists of two elements (corresponding to two GPUs), this
allows the Pipe to work with only two partitions and avoid any
cross-partition overheads.
ntokens = len(vocab.stoi) # the size of vocabulary
emsize = 4096 # embedding dimension
nhid = 4096 # the dimension of the feedforward network model in nn.TransformerEncoder
nlayers = 12 # the number of nn.TransformerEncoderLayer in nn.TransformerEncoder
nhead = 16 # the number of heads in the multiheadattention models
dropout = 0.2 # the dropout value
from torch.distributed import rpc
tmpfile = tempfile.NamedTemporaryFile()
rpc.init_rpc(
name="worker",
rank=0,
world_size=1,
rpc_backend_options=rpc.TensorPipeRpcBackendOptions(
init_method="file://{}".format(tmpfile.name),
# Specifying _transports and _channels is a workaround and we no longer
# will have to specify _transports and _channels for PyTorch
# versions >= 1.8.1
_transports=["ibv", "uv"],
_channels=["cuda_ipc", "cuda_basic"],
)
)
num_gpus = 2
partition_len = ((nlayers - 1) // num_gpus) + 1
# Add encoder in the beginning.
tmp_list = [Encoder(ntokens, emsize, dropout).cuda(0)]
module_list = []
# Add all the necessary transformer blocks.
for i in range(nlayers):
transformer_block = TransformerEncoderLayer(emsize, nhead, nhid, dropout)
if i != 0 and i % (partition_len) == 0:
module_list.append(nn.Sequential(*tmp_list))
tmp_list = []
device = i // (partition_len)
tmp_list.append(transformer_block.to(device))
# Add decoder in the end.
tmp_list.append(Decoder(ntokens, emsize).cuda(num_gpus - 1))
module_list.append(nn.Sequential(*tmp_list))
from torch.distributed.pipeline.sync import Pipe
# Build the pipeline.
chunks = 8
model = Pipe(torch.nn.Sequential(*module_list), chunks = chunks)
def get_total_params(module: torch.nn.Module):
total_params = 0
for param in module.parameters():
total_params += param.numel()
return total_params
print ('Total parameters in model: {:,}'.format(get_total_params(model)))
Out:
Total parameters in model: 1,444,270,191
Run the model¶
CrossEntropyLoss is applied to track the loss and SGD implements stochastic gradient descent method as the optimizer. The initial learning rate is set to 5.0. StepLR is applied to adjust the learn rate through epochs. During the training, we use nn.utils.clip_grad_norm_ function to scale all the gradient together to prevent exploding.
criterion = nn.CrossEntropyLoss()
lr = 5.0 # learning rate
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
import time
def train():
model.train() # Turn on the train mode
total_loss = 0.
start_time = time.time()
ntokens = len(vocab.stoi)
# Train only for 50 batches to keep script execution time low.
nbatches = min(50 * bptt, train_data.size(0) - 1)
for batch, i in enumerate(range(0, nbatches, bptt)):
data, targets = get_batch(train_data, i)
optimizer.zero_grad()
# Since the Pipe is only within a single host and process the ``RRef``
# returned by forward method is local to this node and can simply
# retrieved via ``RRef.local_value()``.
output = model(data).local_value()
# Need to move targets to the device where the output of the
# pipeline resides.
loss = criterion(output.view(-1, ntokens), targets.cuda(1))
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
total_loss += loss.item()
log_interval = 10
if batch % log_interval == 0 and batch > 0:
cur_loss = total_loss / log_interval
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches | '
'lr {:02.2f} | ms/batch {:5.2f} | '
'loss {:5.2f} | ppl {:8.2f}'.format(
epoch, batch, nbatches // bptt, scheduler.get_lr()[0],
elapsed * 1000 / log_interval,
cur_loss, math.exp(cur_loss)))
total_loss = 0
start_time = time.time()
def evaluate(eval_model, data_source):
eval_model.eval() # Turn on the evaluation mode
total_loss = 0.
ntokens = len(vocab.stoi)
# Evaluate only for 50 batches to keep script execution time low.
nbatches = min(50 * bptt, data_source.size(0) - 1)
with torch.no_grad():
for i in range(0, nbatches, bptt):
data, targets = get_batch(data_source, i)
output = eval_model(data).local_value()
output_flat = output.view(-1, ntokens)
# Need to move targets to the device where the output of the
# pipeline resides.
total_loss += len(data) * criterion(output_flat, targets.cuda(1)).item()
return total_loss / (len(data_source) - 1)
Loop over epochs. Save the model if the validation loss is the best we’ve seen so far. Adjust the learning rate after each epoch.
best_val_loss = float("inf")
epochs = 3 # The number of epochs
best_model = None
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train()
val_loss = evaluate(model, val_data)
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | '
'valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss)))
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model
scheduler.step()
Out:
| epoch 1 | 10/ 50 batches | lr 5.00 | ms/batch 990.93 | loss 42.57 | ppl 3061016197728974336.00
| epoch 1 | 20/ 50 batches | lr 5.00 | ms/batch 903.53 | loss 43.66 | ppl 9153379515385631744.00
| epoch 1 | 30/ 50 batches | lr 5.00 | ms/batch 907.54 | loss 41.03 | ppl 659912217209915264.00
| epoch 1 | 40/ 50 batches | lr 5.00 | ms/batch 916.63 | loss 38.26 | ppl 41217240335916624.00
-----------------------------------------------------------------------------------------
| end of epoch 1 | time: 52.48s | valid loss 0.95 | valid ppl 2.57
-----------------------------------------------------------------------------------------
| epoch 2 | 10/ 50 batches | lr 4.51 | ms/batch 1012.99 | loss 34.68 | ppl 1155500231268256.25
| epoch 2 | 20/ 50 batches | lr 4.51 | ms/batch 921.88 | loss 31.80 | ppl 64727715439712.67
| epoch 2 | 30/ 50 batches | lr 4.51 | ms/batch 923.33 | loss 28.55 | ppl 2514245727985.95
| epoch 2 | 40/ 50 batches | lr 4.51 | ms/batch 926.21 | loss 19.73 | ppl 369663903.59
-----------------------------------------------------------------------------------------
| end of epoch 2 | time: 53.29s | valid loss 0.33 | valid ppl 1.39
-----------------------------------------------------------------------------------------
| epoch 3 | 10/ 50 batches | lr 4.29 | ms/batch 1019.19 | loss 12.50 | ppl 269597.20
| epoch 3 | 20/ 50 batches | lr 4.29 | ms/batch 928.48 | loss 10.67 | ppl 42977.71
| epoch 3 | 30/ 50 batches | lr 4.29 | ms/batch 929.41 | loss 9.95 | ppl 21054.85
| epoch 3 | 40/ 50 batches | lr 4.29 | ms/batch 928.28 | loss 9.70 | ppl 16319.99
-----------------------------------------------------------------------------------------
| end of epoch 3 | time: 53.57s | valid loss 0.27 | valid ppl 1.31
-----------------------------------------------------------------------------------------
Evaluate the model with the test dataset¶
Apply the best model to check the result with the test dataset.
test_loss = evaluate(best_model, test_data)
print('=' * 89)
print('| End of training | test loss {:5.2f} | test ppl {:8.2f}'.format(
test_loss, math.exp(test_loss)))
print('=' * 89)
Out:
=========================================================================================
| End of training | test loss 0.24 | test ppl 1.27
=========================================================================================
Output¶
Total parameters in model: 1,847,087,215
| epoch 1 | 10/ 50 batches | lr 5.00 | ms/batch 2387.45 | loss 42.16 | ppl 2036775646369743616.00
| epoch 1 | 20/ 50 batches | lr 5.00 | ms/batch 2150.93 | loss 48.24 | ppl 891334049215401558016.00
| epoch 1 | 30/ 50 batches | lr 5.00 | ms/batch 2155.23 | loss 34.66 | ppl 1125676483188404.62
| epoch 1 | 40/ 50 batches | lr 5.00 | ms/batch 2158.42 | loss 38.87 | ppl 76287208340888368.00
-----------------------------------------------------------------------------------------
| end of epoch 1 | time: 119.65s | valid loss 2.95 | valid ppl 19.15
-----------------------------------------------------------------------------------------
| epoch 2 | 10/ 50 batches | lr 4.51 | ms/batch 2376.16 | loss 34.92 | ppl 1458001430957104.00
| epoch 2 | 20/ 50 batches | lr 4.51 | ms/batch 2160.96 | loss 34.75 | ppl 1232463826541886.50
| epoch 2 | 30/ 50 batches | lr 4.51 | ms/batch 2160.66 | loss 28.10 | ppl 1599598251136.51
| epoch 2 | 40/ 50 batches | lr 4.51 | ms/batch 2160.07 | loss 20.25 | ppl 621174306.77
-----------------------------------------------------------------------------------------
| end of epoch 2 | time: 119.76s | valid loss 0.87 | valid ppl 2.38
-----------------------------------------------------------------------------------------
| epoch 3 | 10/ 50 batches | lr 4.29 | ms/batch 2376.49 | loss 13.20 | ppl 537727.23
| epoch 3 | 20/ 50 batches | lr 4.29 | ms/batch 2160.12 | loss 10.98 | ppl 58548.58
| epoch 3 | 30/ 50 batches | lr 4.29 | ms/batch 2160.05 | loss 12.01 | ppl 164152.79
| epoch 3 | 40/ 50 batches | lr 4.29 | ms/batch 2160.03 | loss 10.63 | ppl 41348.00
-----------------------------------------------------------------------------------------
| end of epoch 3 | time: 119.76s | valid loss 0.78 | valid ppl 2.17
-----------------------------------------------------------------------------------------
=========================================================================================
| End of training | test loss 0.69 | test ppl 1.99
=========================================================================================
Total running time of the script: ( 3 minutes 9.023 seconds)
